Ground Truth Reference
Ground Truth Mixture
Speaker 1 Ground Truth
Speaker 2 Ground Truth

Speaker 3 Ground Truth
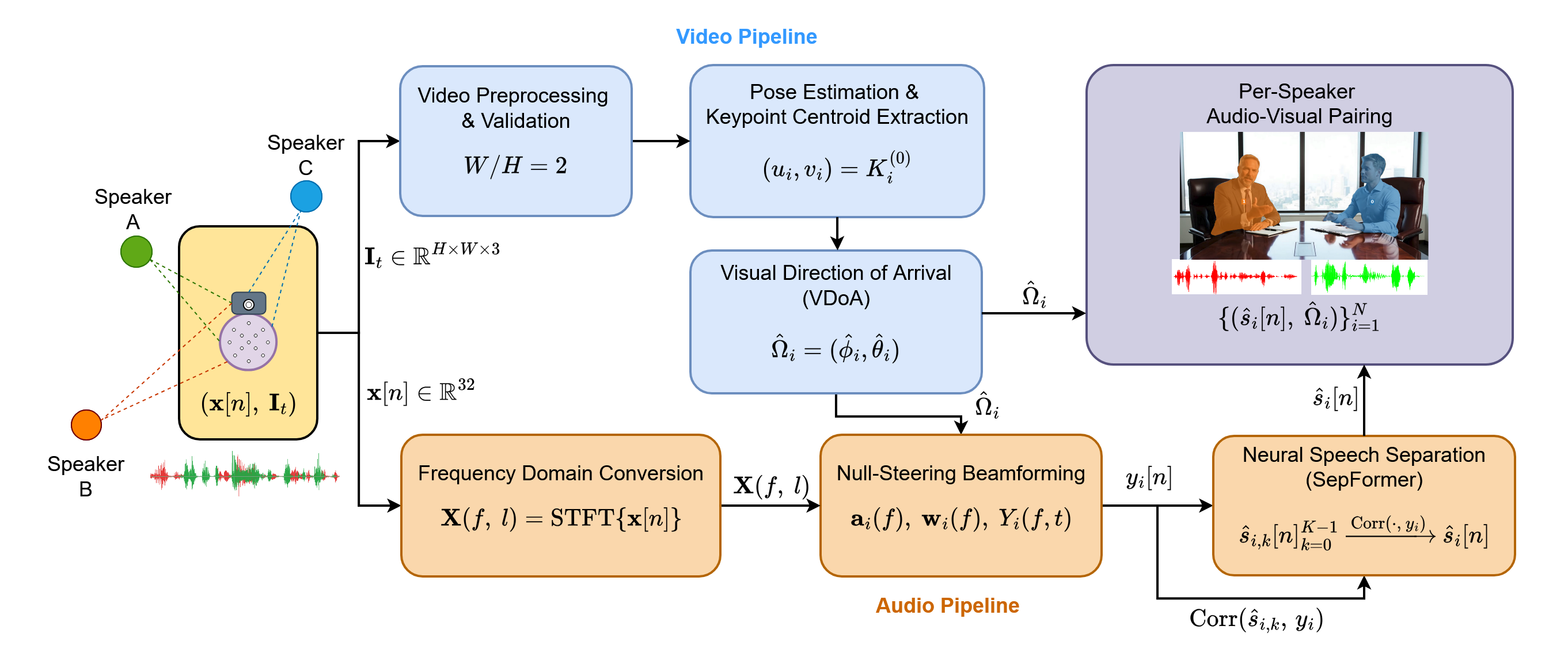
Convolution with RIR
Speaker 1
Speaker 2
Speaker 3
Input Mixture to Proposed System
Beamformer Output
Towards Speaker 1
Towards Speaker 2
Towards Speaker 3
Final Separated Output
Speaker 1 Extracted
Speaker 2 Extracted
Speaker 3 Extracted